The field of presidential candidates has started to heat up and the websites are the first stop for a lot of prospective voters. For my purposes though, I was less interested in their political platform and more curious about the technology behind the websites. Others have already compared the SSL security of the candidates, so I wanted to check out what sort of information the presidential hopefuls' robots.txt files and 404 responses return. To generate the 404 response I chose a random URL /test (turns out I'm really bad at being random).
Without further ado, let me show the results of the requests:
Democrats
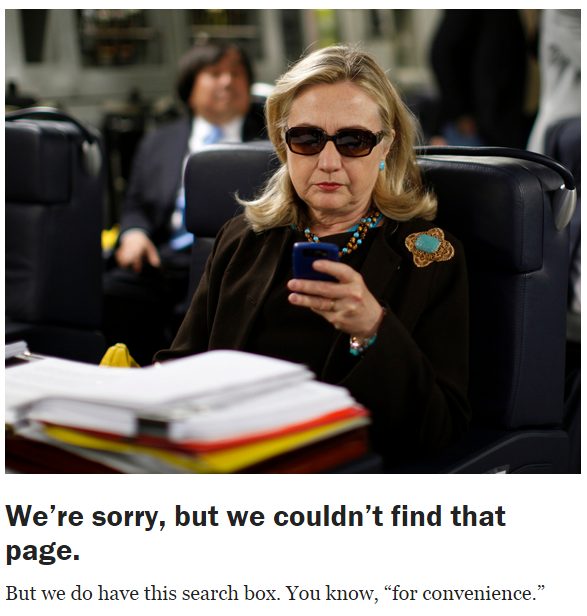
Hillary Clinton
https://www.hillaryclinton.com
robots.txt
User-agent: *
Disallow: /api/
Looks like there's an API for their website that is undocumented publicly.
404

Bernie Sanders
robots.txt
User-agent: *
Disallow: /wp-admin/
The website uses Wordpress as its framework.
404
Martin O'Malley
robots.txt
User-agent: *
Disallow: /wp-admin/
The website uses Wordpress as its framework.
404

Jim Webb
robots.txt
User-agent: *
Disallow: /wp-admin/
Sitemap: http://www.webb2016.com/sitemap.xml
404
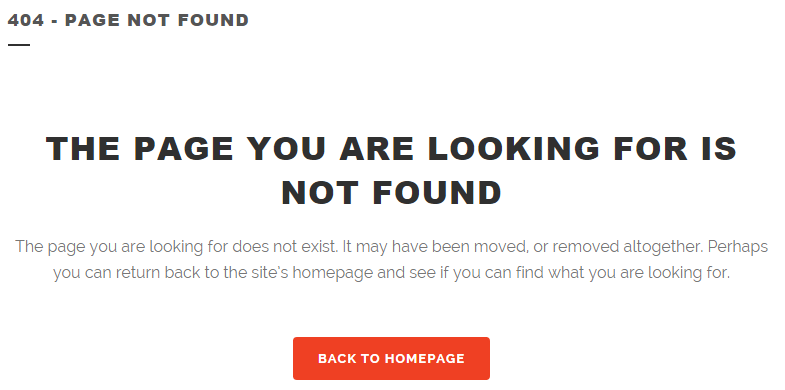
Lincoln Chafee
robots.txt
User-agent: *
Disallow: /wp-admin/
404

Republicans
Jeb Bush
robots.txt
No robots.txt file available.
404
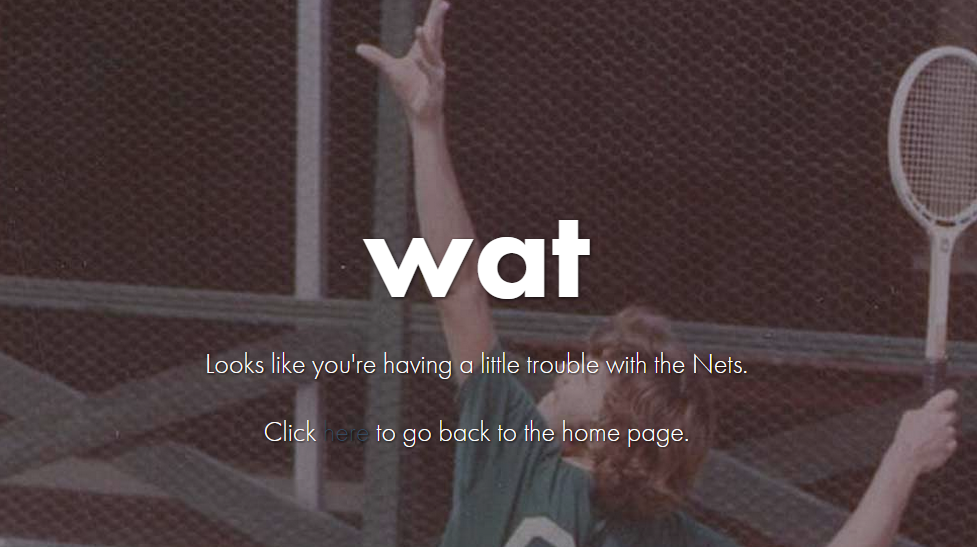
Rand Paul
robots.txt
User-agent: *
Disallow:
404
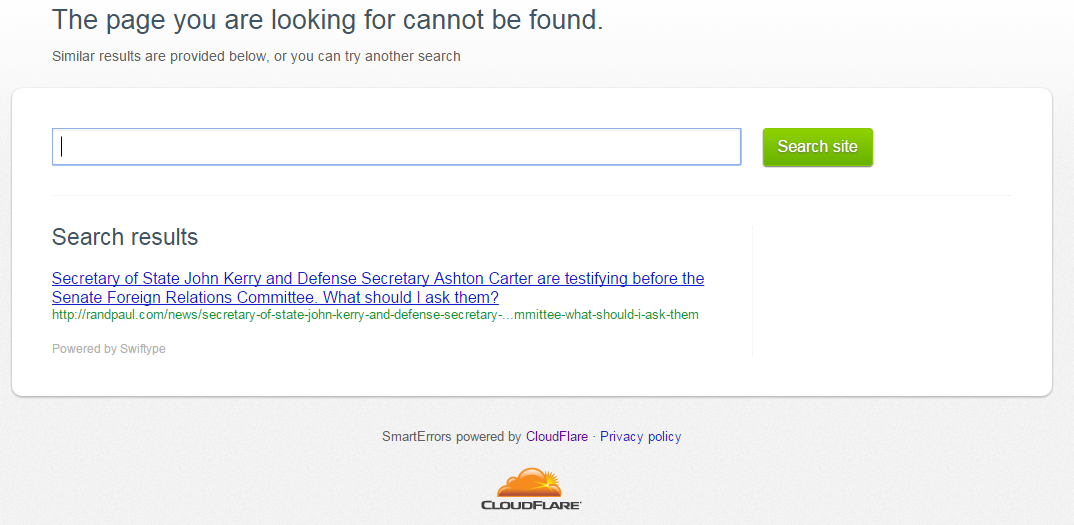
Ted Cruz
robots.txt
User-agent: *
Disallow: /wp-admin/
The website uses Wordpress as its framework.
Rick Santorum
robots.txt
User-Agent: *
Disallow: /admin/
Disallow: /utils/
Disallow: /forms/
Disallow: /users/
Sitemap: http://www.ricksantorum.com/sitemap_index.xml
Based on this information the website is a hosted CMS at nationbuilder.com
404
Ben Carson
robots.txt
No robots.txt file available.
404
Most of them didn't turn out to be very interesting to look at, with the exception of the final candidate I'd like to show:
Carly Fiorina
robots.txt
User-agent: *
Disallow: /standing-desks2
Disallow: /standing-desks2.html
Disallow: /privacy-policy.html
Disallow: /privacy-policy
Disallow: /terms-of-use.html
Disallow: /terms-of-use
Disallow: /adjustable-height-desk.html
Disallow: /adjustable-height-desk
Disallow: /blank
Disallow: /test
404
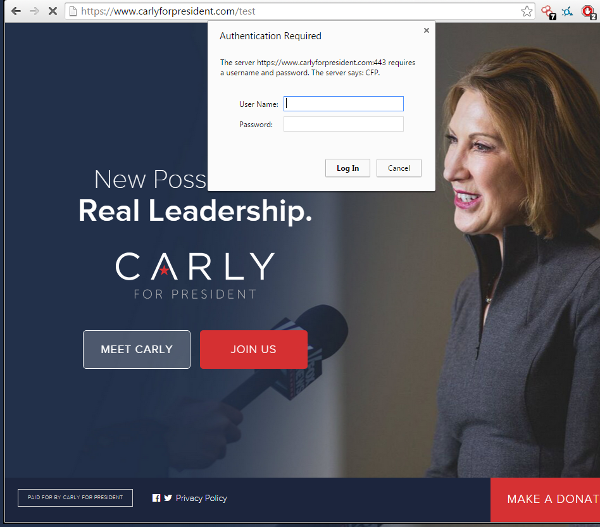
It turned out that my random URL of /test wasn't random enough and I accidentally stumbled upon a location on Carly Fiorina's website that requires authentication.
I took away 4 lessons from this exercise:
- Wordpress remains incredibly popular
- robots.txt can tell you where the administrative area is
- 404s must be generated enough that it is worth investing time into making them nicer
- I'm bad at generating random URLs
PS: Did you know that Shodan also grabs the robots.txt data for each IP? You can access all the information via the Shodan API.