There's been much focus on MongoDB, Elastic and Redis in terms of data exposure on the Internet due to their general popularity in the developer community. However, in terms of data volume it turns out that HDFS is the real juggernaut. To give you a better idea here's a quick comparison between MongoDB and HDFS:
| MongoDB | HDFS | |
|---|---|---|
| Number of Servers | 47,820 | 4,487 |
| Data Exposed | 25 TB | 5,120 TB |
Even though there are more MongoDB databases connected to the Internet without authentication in terms of data exposure it is dwarfed by HDFS clusters (25 TB vs 5 PB). Where are all these instances located?
Most of the HDFS NameNodes are located in the US (1,900) and China (1,426). And nearly all of the HDFS instances are hosted on the cloud with Amazon leading the charge (1,059) followed by Alibaba (507).
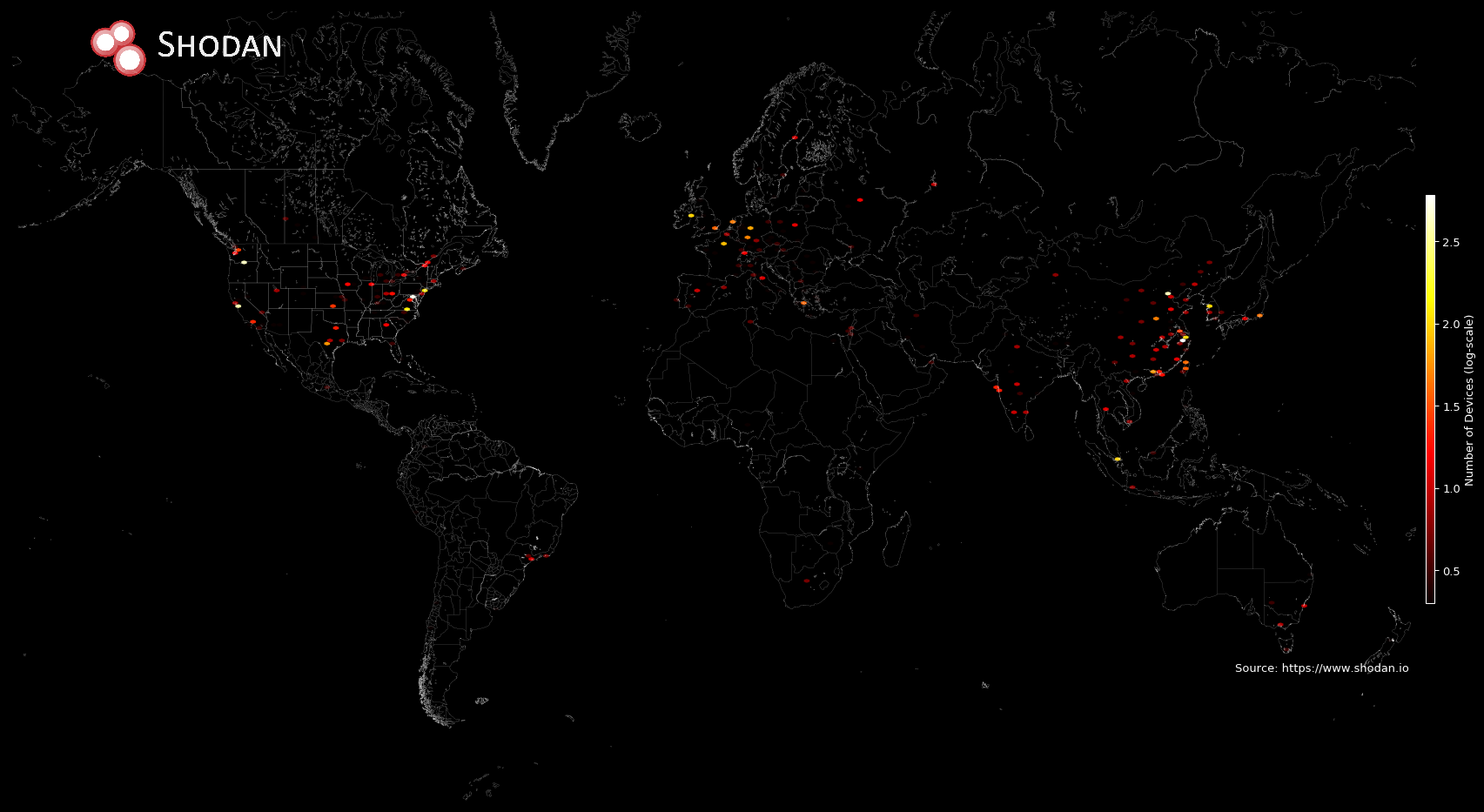
The ransomware attacks on databases that were widely publicized earlier in the year are still happening. And they're impacting both MongoDB and HDFS deployments. For HDFS, Shodan has discovered roughly 207 clusters that have a message warning of the public exposure. And a quick glance at search results in Shodan reveals that most of the public MongoDB instances seem to be compromised. I've previously written on the reason behind these exposures but note that both products nowadays have extensive documentation on secure deployment.
Technical Details
If you'd like to replicate the above findings or perform your own investigations into data exposure, this is how I measured the above.
Download data using the Shodan command-line interface:
shodan download --limit -1 hdfs-servers product:namenodeWrite a Python script to measure the amount of exposed data (hdfs-exposure.py):
from shodan.helpers import iterate_files, humanize_bytes from sys import argv, exit if len(argv) <=1 : print('Usage: {} <file1.json.gz> ...'.format(argv[0])) exit(1) datasize = 0 clusters = {} # Loop over all the banners in the provided files for banner in iterate_files(argv[1:]): try: # Grab the HDFS information that Shodan gathers info = banner['opts']['hdfs-namenode'] cid = info['ClusterId'] # Skip clusters we've already counted if cid in clusters: continue datasize += info['Used'] clusters[cid] = True except: pass print(humanize_bytes(datasize))Run the Python script to get the amount of data exposed:
$ python hdfs-exposure.py hdfs-data.json.gz 5.0 PB